Inference Is Not HTTP: The Case for a Purpose-Built Gateway in Rust

Every production LLM stack I have seen has the same hidden weak point: the API layer in front of the model. Teams ship it as a Python shim, an Envoy filter, an NGINX rewrite, or a thoughtful combination of all three — sensible reuse of mature pieces. Most days it works. On the days it doesn’t, you discover at exactly the wrong moment that the thing you thought was a load balancer is actually the most consequential piece of infrastructure in your stack.
I am building an inference gateway in Rust. This post is why — the technical case, the engineering case, and the why now.
If you serve LLMs at scale, you will reach the same conclusion eventually. I am writing this so you reach it before the 3 AM page rather than during.
The Problem: Inference Is Not HTTP
Conventional API gateways were designed for stateless HTTP-RPC: small request in, fast response out, billions of times per second. Envoy, NGINX, HAProxy, Traefik — all exquisitely tuned for that workload.
LLM inference breaks every assumption in that pipeline:
| Assumption | Reality of inference |
|---|---|
| Requests are small | A chat completion with 8K input tokens is 30-100 KB |
| Responses are small | Streaming responses run into megabytes |
| Requests are fast | Latency ranges from 50 ms to 60+ seconds |
| Requests are stateless | KV-cache reuse across turns is the difference between $0.01 and $0.10 |
| Requests are equal | A 100-token prompt and an 8000-token prompt cost wildly different GPU time |
| Backends are interchangeable | An H100 with FP8 vLLM and an A100 with FP16 are not the same backend |
| Failure is HTTP 5xx | Failure modes include OOM mid-stream, repeat-loop generation, malformed tokens, and silent truncation |

Treating inference traffic like HTTP traffic produces exactly what you would expect: ugly tail latencies, terrible GPU utilization, and outage modes that don’t appear in any traditional load-balancer dashboard.
The infrastructure category for this — call it the inference gateway — does not exist as a mature product yet. Everyone is rolling their own, and the early implementations are doing real work in production. We are early enough that getting the abstractions right now will define the next decade of LLM-serving architecture.
What an Inference Gateway Actually Has to Do
This is the list. It is longer than most people think.
Token-aware routing
- Input/output token budgets per request, per tenant, per model
- Estimated GPU-seconds per request before dispatch
- Backend’s current token-per-second headroom
- Prefill/decode disaggregation when the backend supports it

GPU-aware backend selection
- Which SKU is healthy and how much spare capacity it has
- Which has the requested model loaded (cold-loading a 70B model takes minutes)
- Which has the right quantization (FP16, FP8, INT4) for the latency target
- Affinity for multi-turn sessions to maximize KV-cache reuse
Streaming with surgical backpressure
- Server-Sent Events, token streams, raw chunked transfer
- Cancellation propagation — when a client disconnects, the GPU slot must free now, not at end-of-stream
- Token-level metrics emitted as the stream flows
- Speculative-decoding awareness (don’t double-count drafted tokens)

Cache-aware routing
- Prefix matching to land repeat prompts on warm KV caches
- Sticky routing for chat sessions
- Aware of disaggregated KV-cache transport when the backend supports it
Protocol mediation
- OpenAI-compatible API as the public contract
- Translation to backend dialects (TensorRT-LLM, vLLM, SGLang, NIM, llama.cpp, raw HTTP)
- Chat → completion → embedding → reranking shape conversion
- Tool / function-calling schema normalization
Prompt security and guardrails
- Prompt-injection and jailbreak screening at the request boundary
- PII, secret, and regulated-data detection before tokens leave the trust boundary
- Tool-call authorization before the model can touch files, APIs, browsers, or code
- Shadow-AI visibility for employee traffic going to public GenAI tools
- Policy enforcement that lives outside the agent’s own prompt
- Red-team findings wired back into runtime controls, not parked in a PDF

This is where the emerging prompt-security market is instructive. Vendors are clustering around different slices: Prompt Security focuses on shadow AI, GenAI authorization, and guardrails; Lasso and Lakera emphasize runtime protection; Protect AI, now part of Palo Alto Networks, has pushed model supply-chain and scanning; Dynamo AI leans into privacy and compliance guardrails; WitnessAI targets governance and visibility; Mindgard brings automated AI red teaming into CI/CD; Knostic focuses on knowledge access control for tools like Copilot, Glean, and Gemini.
The gateway does not need to replace all of that. It needs to provide the enforcement point where those decisions become real. A system prompt saying “do not leak secrets” is a suggestion. A gateway that blocks the outbound request, strips sensitive context, denies a tool call, and records the policy decision is infrastructure.
Cost and quota
- Per-tenant input-token, output-token, and total-token budgets
- Per-model rate limits
- Real-time spend tracking, not nightly batch
- Cost-aware fallback (route to cheaper backend if budget tight)
Resilience
- Health based on token throughput, not HTTP 200s — a backend that returns 200s but produces garbage tokens is unhealthy
- Retries that respect cancellation and don’t double-charge tokens
- Per-(model, GPU-SKU) circuit breakers
- Graceful degradation, not binary up/down
Observability
- Per-request: input tokens, output tokens, prefill latency, time-to-first-token, inter-token latency
- Per-backend: queue depth, batch fill rate, GPU utilization
- Per-tenant: spend, P99, error rates segmented by reason
This is not a load balancer. It is a domain-specific control plane for LLM traffic. Building it on top of NGINX or as an Envoy filter is workable for a while — those projects are extraordinarily capable — but the workload eventually outgrows the abstractions they were optimized for. At that point the shape of the problem starts asking for a purpose-built tool.
Before writing a line of gateway code, I would insist on one design artifact: a request lifecycle that names every resource the request can hold. Tokens, model slots, KV blocks, stream buffers, retry budget, trace span, tenant budget, and cancellation handle all need owners. If the lifecycle diagram cannot explain when each one is released, the implementation will eventually leak one of them.
Why Rust
I evaluated four serious candidates:
| Python (FastAPI) | Go | C++ (Envoy filter) | Rust | |
|---|---|---|---|---|
| Memory safety | OK (GC) | OK (GC) | Manual, error-prone | Compile-time enforced |
| GC tail latency | Bad (GC + GIL) | Real (~1 ms pauses) | None | None |
| Throughput ceiling | Low (GIL) | Good | Highest | Highest |
| Async model | asyncio + GIL | Goroutines | Event loop / threads | Tokio (mature) |
| Binary | Interpreter required | ~15 MB | ~50 MB + filter Lua | ~10 MB single static |
| HTTP/gRPC stack | Starlette, FastAPI | net/http, gRPC-Go | Envoy/proxy-wasm | hyper, axum, tonic |
| Iteration speed | Fastest | Fast | Painful | Moderate |
| Long-tail predictability | Bad | OK | Good | Excellent |
The four properties that decided it for me:
1. Predictable tail latency. Every GC pause is a token batch missed. Tokio’s no-GC, structured-concurrency model means a P99 that does not surprise you under load. For Go this is “usually fine, sometimes mysterious.” For Python this is “good luck.” For Rust this is structural.
2. Cost of bugs is enormous. A memory leak in an inference gateway can waste serious token budget. A use-after-free in the streaming path can become a security issue. Rust’s compile-time guarantees are not a luxury here — they are one of the strongest practical defenses available for this class of component.
3. Async is the workload. Inference is long-lived, streaming, cancellable. Tokio’s select!, structured cancellation, and the maturing async fn in traits story give Rust strong ergonomics for this shape of work without putting a garbage collector in the hot path.
4. Single static binary. Deploy one binary. No Python wheels, no JVM warmup, no 600 MB Docker image. Cold start matters when an inference gateway is the bottleneck on autoscale events.
Receipts, not vibes
Ben Dicken keeps a running benchmark — 1 billion nested loop iterations across 14 languages — that captures the floor of compute overhead each runtime imposes. The numbers tell the same story I have seen in production over and over:
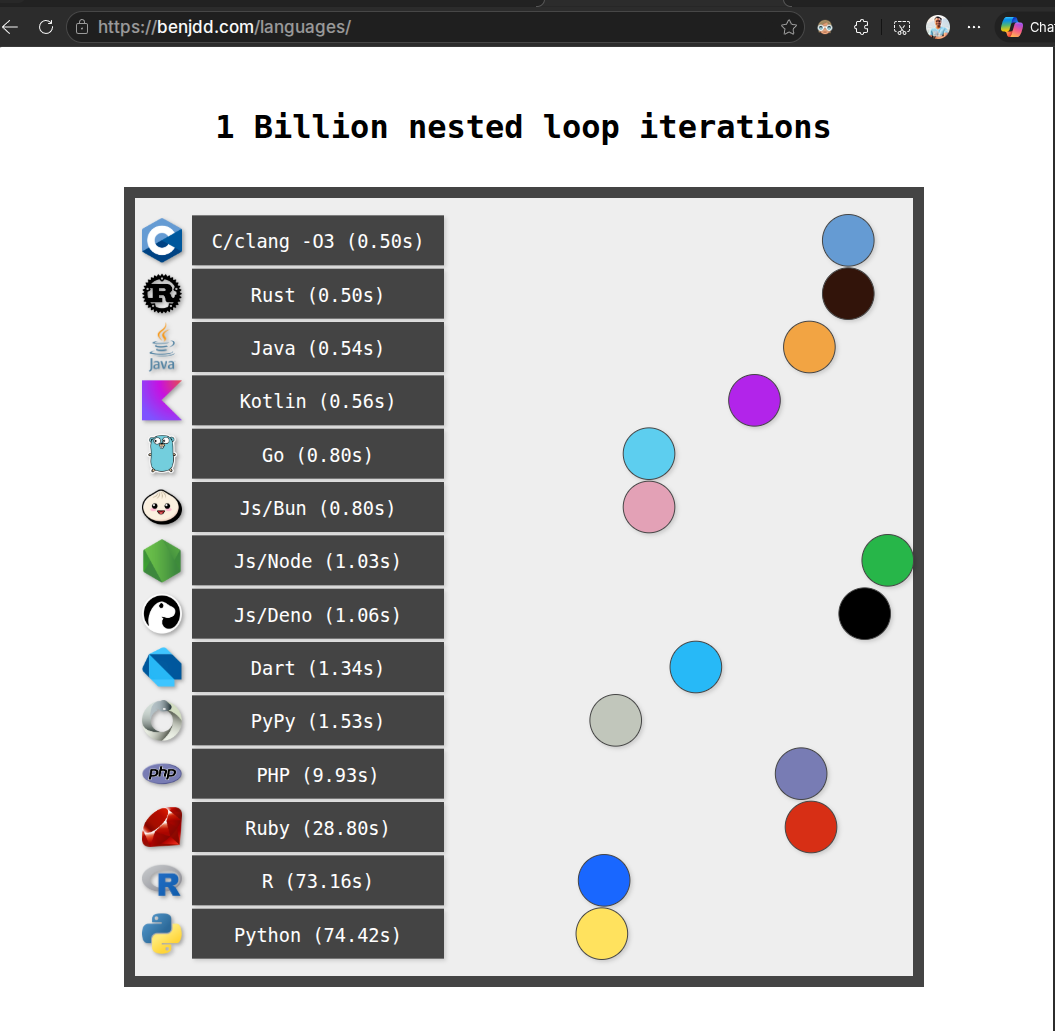
| Language | Time | Penalty vs Rust |
|---|---|---|
| C/clang -O3 | 0.50s | tie |
| Rust | 0.50s | baseline |
| Java | 0.54s | 1.08× |
| Kotlin | 0.56s | 1.12× |
| Go | 0.80s | 1.60× |
| Js/Node | 1.03s | 2.06× |
| Python | 74.42s | ~149× |
A microbenchmark is not a gateway workload. It does not measure TLS, kernel networking, backpressure, allocator behavior, metrics, JSON, tokenization, or backend latency. What it does provide is a useful floor: Rust can sit near C-level CPU overhead when the code is simple and optimized.
For a control plane sitting in front of a multi-million-dollar GPU fleet, that floor matters, but only after the design is correct. Rust gives you a low overhead baseline plus memory-safety guarantees. The gateway still has to earn its keep through routing, cancellation, and observability.
Go was the close second. It lost on tail latency under sustained load. For 90% of services Go’s GC is irrelevant; for the gateway in front of an inference cluster running at 80% utilization, every millisecond is real.
C++ + Envoy is a strong, battle-tested option. Envoy is one of the best-engineered proxies of the past decade, and teams already running it at scale start with a real head start: mTLS, ext_authz, retries, observability hooks — all mature. The trade-offs are non-trivial inference logic ending up in C++ or Lua filters, and carrying Envoy’s operational footprint in the hot path. For organizations already deep in Envoy, it’s the obvious path. For greenfield, I think a smaller, single-purpose binary is the better fit.
Architecture, in One Diagram

Each block in that diagram is a Rust module with a single, well-defined responsibility. The data flow is one-way except for the streaming path, which is bidirectional with explicit cancellation. The state is mostly in-memory, lock-free where possible, with a small persistent layer for budgets and audit.
Why Now
Three things converged in the last 18 months that make this the right moment to build:
1. The OpenAI-compatible API shape has become the common denominator. Most serious model servers and hosted providers now expose something close enough that a gateway can normalize the public contract and adapt backend dialects behind it. That standardization was not real two years ago. Now it is useful enough to build around.
2. Rust async has matured. async fn in traits is stable. tokio::select! is rock solid. axum 0.7+ has the ergonomics of FastAPI. tonic gives us first-class gRPC. The pieces that were missing in 2022 are present and working in production at multiple companies.
3. Inference is now infrastructure, not a science project. Three years ago many teams served one model on a few GPUs. In 2025 and 2026, serious platforms serve many models across heterogeneous H100 / H200 / B200 / GB200 / GB300 fleets, with multiple quantizations, multiple runtimes, and cost budgets denominated in hundreds of millions of tokens per day. The control plane around that has to be a real product, not a Python sidecar.
The teams that own the control-plane layer for inference will own a meaningful piece of the AI infrastructure stack for the next decade. It is the same pattern as Envoy/Cloudflare for HTTP, Kafka for streaming, Kubernetes for compute. Inference is next.
How This Differs From What Exists
These projects all do good work; my goal is a different scope, not a critique. Each one is a fine choice for the problem it was built to solve.
- vs litellm — litellm is excellent at what it sets out to do: a Python library that gives you one interface across many model providers. Great for a small or single-tenant deployment. The scope I am after sits one layer down: multi-tenant control plane, cancellation-safe streaming, GPU awareness, first-class observability.
- vs LangChain / LlamaIndex — both are powerful SDKs and orchestration frameworks, and they have done a lot to popularize agentic patterns. They solve a different problem (application-level composition) than a network-edge gateway.
- vs Envoy + ext_authz / Lua filter — Envoy is a remarkable piece of infrastructure and arguably the best-engineered proxy in production today. Its weakness for this specific workload is that it is protocol-blind to inference: token-awareness, cache-affinity routing, and cancellation-safe streaming can be added but are expensive to bolt on. For teams already committed to Envoy, this is a viable path.
- vs NGINX + OpenResty — NGINX is one of the most battle-tested servers ever shipped, and OpenResty has carried serious workloads for over a decade. The same shape of trade-off applies as with Envoy: adding inference semantics is doable, but streaming and cancellation ergonomics are harder to land cleanly.
- vs vendor-specific gateways — the right choice when you are committed to a single model vendor and want their full feature surface. The reason for a separate gateway is heterogeneity across vendors and SKUs.
- vs raw FastAPI in front of vLLM — genuinely fine for a single model on a single cluster, and a great way to ship fast. The constraints show up the moment you add a second model or a second backend SKU.
The right comparison is: imagine Cloudflare Workers redesigned from scratch for LLM traffic, in Rust, as a single binary you can drop into your cluster. That is the target shape.
What I Am Optimizing For
When I sit down to work on this, the priority order is fixed:
- Correctness. A misrouted token stream is a multi-cluster debug session. Make routing decisions provably correct or don’t make them.
- Tail latency. P99 should degrade predictably when load doubles. P99.9 should not collapse because one backend dies.
- Operational simplicity. One binary. One config file. Reload without dropping connections. Health endpoints that mean what they say.
- Throughput. Once 1-3 are nailed, throughput follows. Optimizing for throughput first usually breaks 1-3.
Notice what is not on the list: feature breadth. The MVP must do five things flawlessly, not fifty things badly. The temptation in any greenfield project is to absorb every adjacent concern. Resist.
Honest Trade-offs
Rust is not free. The trade I am paying:
- Slower iteration than Python. A new endpoint takes a day, not an hour. Borrow checker fights early; they shrink with experience but never go to zero.
- Smaller pool of contributors. Hiring or borrowing engineers comfortable in async Rust is harder than hiring Python engineers.
- Debugging is harder. A panic in tokio’s runtime gives you a stack trace that is initially incomprehensible. Reading async stack traces is a skill.
I am paying these costs deliberately. The properties they buy — predictable tail latency, no GC pauses, structurally enforced memory safety, single-binary deploy — are non-negotiable for the workload.
If you don’t need those properties, don’t pay these costs. Python in front of vLLM is genuinely fine for a single model with moderate scale. Pick deliberately.
Build vs Buy
The honest call:
- <100M tokens/day on one model: don’t build. FastAPI in front of vLLM, or one of the open gateways (OpenRouter, litellm) is sufficient.
- >500M tokens/day on multiple models, multiple GPU SKUs: you will build, or you will adopt something close. The off-the-shelf options have not caught up to the requirements yet.
- Between: start with an OSS gateway, instrument the hell out of it, and rebuild the parts that hurt. Most of those parts are routing, observability, and cancellation safety. Coincidentally, those are the parts where Rust pays off.
Whether you build or adopt, the design principles are the same. Token-aware routing. Cancellation safety. GPU-aware health. Single binary. Observability designed for tokens, not for HTTP.
What I Will Be Posting About Next
This is the foundational post. The follow-ups I have queued:
- The cancellation-safety problem in streaming inference, and how Tokio makes it tractable
- Token-aware load balancing: why round-robin is wrong and what to do instead
- Prefix-cache-aware routing and the operational case for sticky sessions
- Observability for inference: the metrics that actually predict outages
- Why the gateway is the right place for cost governance, and what that looks like
If you are building in this space, I want to compare notes. The community of people doing this seriously is small, and the design choices we are all making in 2025 will be the defaults for years. We should get them right.
Closing
Inference is becoming one of the defining AI infrastructure workloads. The control plane around it — auth, routing, cost, reliability, streaming, observability — needs to be a first-class system, not a stack of duct-tape on infrastructure designed for 2010-era microservices.
Rust is the right substrate because the tail-latency requirements are real, the cost of bugs is enormous, and the async ecosystem has finally matured. Go is a strong second; everything else is a third place.
I am building it. I will share what I learn. If you are doing the same — write to me. Let’s compare notes.
Sources and receipts
- Rust async and trait maturity: Rust 1.75 release notes and Tokio.
- Runtime overhead benchmark used as a sanity check, not a gateway benchmark: Ben Dicken’s language race.
- Inference-aware routing direction in Kubernetes: Gateway API Inference Extension and project repository.
- NVIDIA distributed inference context: Dynamo overview and Dynamo architecture docs.
- Engine/server examples behind a gateway: TensorRT-LLM docs, vLLM docs, and SGLang docs.
- Prompt-security risk taxonomy: OWASP Top 10 for LLM Applications and LLM01 Prompt Injection.
- Prompt-security vendor references: Prompt Security Shadow AI, Lasso AI Security Platform, Lakera Guard, Palo Alto Networks acquisition of Protect AI, DynamoGuard, WitnessAI, Mindgard automated AI red teaming, and Knostic Copilot Governance.